
实时光线追踪[1]: Vulkan Ray-Tracing Pipeline
- Ray-Tracing pipeline in Vulkan
- Ray-Tracing reflection and refraction
- Different geometry types in acceleration structure
- Heightmap based water simulation and caustics rendering
- Other features in Ray-Tracing Pipeline
- Vulkan synchronization: Fence, Femaphore and Pipeline-barriers
- Miscellaneous
- References
光线追踪和光栅化是实时渲染中常见的两种解决方案。由于光栅化天生适合并行加速(例如数据局部性较好), 最早的GPU硬件便是为光栅化渲染而设计的。近年来,NVIDIA、AMD、Intel等厂商纷纷推出专门加速光线追踪计算的硬件单元, 使得硬件加速光线追踪逐渐成为可能。即使在移动端,许多高端芯片也开始推出针对性的硬件支持光线追踪, 例如Ray Query,以及Ray-Tracing Pipeline,这些技术有望在不远的将来普及(本文写于2024年11月)。
为了深入了解Vulkan Ray-Tracing Pipeline,笔者在开源框架 Vulkan-Samples 上实现了一个场景, 展示了光线追踪反射、折射、水面高度场的模拟、Caustics生成和渲染等效果。在实现过程中, 水面高度场的模拟采用了Vulkan Compute Pipeline,Caustics的生成使用了Graphics Pipeline, 最终效果的渲染则通过Ray-Tracing Pipeline完成。该过程涉及到渲染资源的组织与同步、 Ray-Tracing Pipeline中加速结构的构建以及不同类型shader的应用等内容。
本文主要作为个人学习笔记,可能存在不足之处或不准确之处,欢迎读者批评指正。
Ray-Tracing pipeline in Vulkan
以Kajiya的渲染方程为理论基础,光线追踪是一种基于相机位置为原点,向渲染图像中的每个像素发射多条光线的技术。 这些光线以一定的概率穿越场景,模拟光线在场景中的反射、折射、吸收及表面着色,最终计算得到像素的颜色 (具体过程详见蒙特卡洛积分)。为了加速蒙特卡洛积分的收敛速度,高效的采样与降噪方法成为加速光线追踪效果收敛的关键。 有关光线追踪的详细信息,可以参考以下链接: Ray Tracing in One Weekend 和 蒙特卡洛积分。
Vulkan 是一个高性能的跨平台图形和计算 API,由Khronos Group 维护。为了支持光线追踪,Khronos 在Vulkan中引入了一系列扩展:
- VK_KHR_ray_tracing_pipeline:允许开发者使用专用的着色器(如Ray Generation、Intersection 和 Closest Hit 着色器)来实现光线追踪效果。
- VK_KHR_acceleration_structure:提供操作加速结构的功能,例如创建和更新BVH(包围体层次结构)。
- VK_KHR_ray_query:允许在任何着色器阶段使用光线查询功能,而无需构建完整的光线追踪管线,常用于阴影和AO(环境光遮蔽)渲染。
- VK_KHR_deferred_host_operations 和 VK_KHR_pipeline_library 等扩展:优化加速结构的构建和光线追踪管线的加载性能。
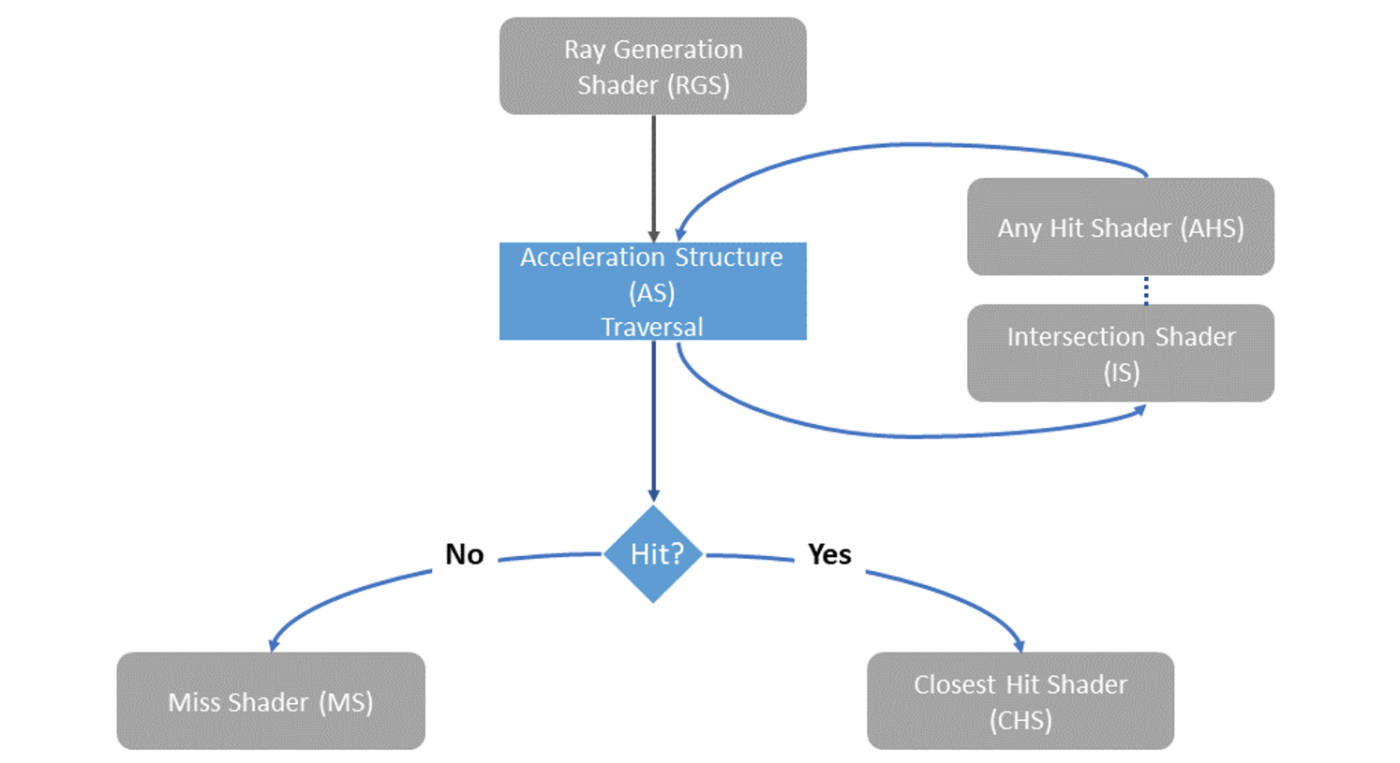
下图展示了Vulkan Ray-Tracing Pipeline的流程。在每个像素点执行Ray Generation Shader, 发射相关光线,光线射向预先构建好的加速结构。然后,Intersection Shader判断光线是否与场景中的物体相交, 并获取交点信息。如果相交,执行相关的Hit Shader,否则执行Miss Shader。 Hit Shader包括Closest Hit Shader和Any Hit Shader:前者在光线追踪后, 处理离原点最近的交点,后者则在每个击中点都执行,常用于渲染半透明效果等。
vkCmdTraceRaysKHR 是Vulkan中的光线追踪执行指令,类似于 vkCmdDispatch 和 vkCmdDrawIndexed,
用于发起光线追踪计算。它的主要参数如下所示:
void vkCmdTraceRaysKHR(
VkCommandBuffer commandBuffer,
const VkStridedDeviceAddressRegionKHR* pRaygenShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pMissShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pHitShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pCallableShaderBindingTable,
uint32_t width,
uint32_t height,
uint32_t depth
);
在光线追踪中,Shader Binding Table (SBT) 扮演着非常重要的角色。 它能够将一个或多个着色器与其资源进行绑定,并且允许GPU在光线追踪过程中高效地切换和执行不同的着色器。 SBT的使用极大提升了光线追踪过程中的灵活性和性能。
此外,Vulkan中还引入了Shader Group的概念,通过 VkRayTracingShaderGroupCreateInfoKHR
结构体来组织具体的着色器。例如,closestHitShader 有几种不同的类型。如果类型为
VK_RAY_TRACING_SHADER_GROUP_TYPE_TRIANGLES_HIT_GROUP_KHR,则表示该着色器会对几何体数据
执行光线与三角形的求交操作,获取命中的信息。而如果使用 VK_RAY_TRACING_SHADER_GROUP_TYPE_PROCEDURAL_HIT_GROUP_KHR
类型的 closestHitShader,则表示几何体不是三角网格,而是用户自定义的形状,此时需要提供相应的
intersectionShader 来处理光线与该几何体的相交计算。
Ray-Tracing reflection and refraction
在本场景中,只考虑了镜面反射,反射光线仅有一条,折射路径也只有一条。相比之下,漫反射和散射的情况 更为复杂,涉及到复杂的采样和降噪算法(这也是实时光线追踪渲染器中非常关键的问题)。由于本场景的 重点是学习Vulkan光线追踪管线的使用,因此漫反射和散射的处理暂不讨论,留待后续学习中深入探讨。
反射定律和折射定律是常见的物理规律,其数学表达也相对简单。光线的反射和折射本质上是一个递归过程。 然而,过多的递归会导致性能瓶颈,影响光线追踪的效率。参考 Vulkan Sample Ray-Tracing Reflection Case 中的实现,我们可以通过迭代方式设置反射/折射的最大深度,这种方式更加适合SIMD架构,有助于线程的均匀执行, 并且这种明确的循环结构便于编译器进行优化,例如通过寄存器优化内存访问次数等。
// Reflection
vec4 origin = init_origin;
vec4 direction = init_direction;
vec3 color = vec3(1.0);
for (int i = 0; i < MAX_RECURSION; i++)
{
traceRayEXT(topLevelAS, gl_RayFlagsNoneEXT, 0xff, 0, 0, 0, origin.xyz, tmin, direction.xyz, tmax, 0);
vec3 hitColor = rayPayload.color;
if (rayPayload.distance < 0.0f)
{
color *= hitColor + 0.0001 * absortion;
break;
} else if (rayPayload.reflector > 0.5f)
{
color = mix(color, hitColor, absortion);
const vec4 hitPos = origin + direction * rayPayload.distance;
// Do reflection and update ray origin and direction
origin.xyz = hitPos.xyz + rayPayload.normal * 0.001f;
direction.xyz = reflect(direction.xyz, rayPayload.normal);
} else if (rayPayload.refractor > 0.0f)
{
color = mix(color, hitColor, absortion);
const vec4 hitPos = origin + direction * rayPayload.distance;
vec3 refractNormal;
// Calculate refraction for double-sided surface
if (rayPayload.refractor < 1.0f)
{
refractNormal = rayPayload.normal;
}
else
{
refractNormal = -rayPayload.normal;
}
// Do refraction and update ray origin and direction
origin.xyz = hitPos.xyz - refractNormal * 0.001f;
direction.xyz = refract(direction.xyz, refractNormal, rayPayload.refractor);
} else
{
color *= hitColor + 0.0001*absortion;
break;
}
}
hitValues += color;
Different geometry types in acceleration structure
光线追踪算法中计算光线与几何体的相交过程极为耗时,所以需要相应的加速结构来缓解这一过程。 硬件加速的光线追踪,其中的加速主要就是相关的加速结构,Vulkan API中与加速结构相关的图示如下
typedef struct VkAccelerationStructureInstanceKHR {
VkTransformMatrixKHR transform;
uint32_t instanceCustomIndex:24;
uint32_t mask:8;
uint32_t instanceShaderBindingTableRecordOffset:24;
VkGeometryInstanceFlagsKHR flags:8;
uint64_t accelerationStructureReference;
} VkAccelerationStructureInstanceKHR;

可以看到,在Top Level Acceleration Structure (TLAS)中包含了多个Instance,每个Instance对应一个或 多个Bottom Level Acceleration Structure (BLAS)。从图示中可以看出,不同的Instance可以与同一个 BLAS连接,同时它们可以有各自不同的变换矩阵,从而实现将相同几何体放置在场景中的不同位置。
此外,BLAS还允许自定义几何体,例如可以通过公式定义一个球体,但需要显式地给出BLAS的AABB(轴对齐包围盒)。
当不同的BLAS需要执行不同的着色器时(例如三角网格组成的BLAS和基于程序化几何体的BLAS需要执行不同的
closestHitShader和intersectionShader),可以通过设置instanceShaderBindingTableRecordOffset
来实现相应的绑定。
同时,instanceCustomIndex可以作为BLAS的唯一标识传递给着色器,这样可以方便地在GPU中针对不同的几何体执行相应的操作。
球体相关的intersection逻辑参考如下:
struct Sphere {
vec3 center;
float radius;
};
// Ray-sphere intersection
// By Inigo Quilez, from https://iquilezles.org/articles/spherefunctions/
float sphIntersect(const Sphere s, vec3 ro, vec3 rd)
{
vec3 oc = s.center - ro;
float b = dot(oc, rd);
float c = dot(oc, oc) - s.radius * s.radius;
float h = b * b - c;
if (h < 0.0) {
return -1.0;
}
h = sqrt(h);
return b - h;
}
两个三角形组成的矩形的intersection逻辑如下:
struct Plane
{
vec4 center;
vec4 normal;
vec4 points[4];
};
/*
// o: origin, 3-dimension
// d: direction, 3-dimension
// h: distance, scalar
// n: plane normal
// line: o + h * d
// Intersection point of a line and a plane:
// dot(o + h * d - c, n) = 0
// h = dot(c - o, n) / dot(d, n)
// Then check if intersection point is in the rectangle.
*/
float planeIntersect(const Plane p, vec3 ro, vec3 rd)
{
float h = dot(p.center.xyz - ro, p.normal.xyz) / dot(rd, p.normal.xyz);
vec3 hPoint = ro + h * rd;
bool valid = false;
// Test first triangle
{
vec3 v1 = p.points[0].xyz/p.points[0].w - hPoint;
vec3 v2 = p.points[1].xyz/p.points[1].w - hPoint;
vec3 v3 = p.points[2].xyz/p.points[2].w - hPoint;
if (length(v1) == 0 || length(v2) ==0 || length(v3) == 0)
{
valid = true;
}
else
{
vec3 v4 = cross(v1, v2);
vec3 v5 = cross(v2, v3);
vec3 v6 = cross(v3, v1);
float v7 = dot(v4, v5);
float v8 = dot(v5, v6);
bool inside = v7 >= 0.0 && v8 >= 0.0;
valid = valid || inside;
}
}
// Test second triangle
{
vec3 v1 = p.points[2].xyz/p.points[2].w - hPoint;
vec3 v2 = p.points[3].xyz/p.points[3].w - hPoint;
vec3 v3 = p.points[0].xyz/p.points[0].w - hPoint;
vec3 v4 = cross(v1, v2);
vec3 v5 = cross(v2, v3);
vec3 v6 = cross(v3, v1);
float v7 = dot(v4, v5);
float v8 = dot(v5, v6);
bool inside = v7 >= 0.0 && v8 >= 0.0;
valid = valid || inside;
}
if (!valid)
return -1.0;
return h;
}
Heightmap based water simulation and caustics rendering
为了增强交互性,我们在场景中加入了一个基于高度场的水面模拟和Caustics渲染,并实现了与鼠标的交互。 高度场和Caustics渲染的相关算法参考了 Evan Wallace 的 WebGL Water 实现。 水面通过一个高分辨率的高度场图像来表示,该图像包含四个通道:相对高度、海面高度变化的速度, 以及法线向量归一化后的x和z分量。
用户通过鼠标点击来确定水面的位置,触发一个扰动(Drop Shader)。之后,水面根据高度场数据 更新高度(Height)和速度(Velocity),并最终更新高度场的法线(Normal)。这一算法结构清晰,具体算法 可以参考相下列Shader代码。
// Drop Shader
/* add the drop to the height */
float drop = max(0.0, 1.0 - length(center - coords) / radius);
drop = 0.5 - cos(drop * PI) * 0.5;
info.r += drop * strength;
// Update height
ivec2 texelCoords = ivec2(gl_GlobalInvocationID.xy);
vec4 info = imageLoad(waterHeightMap, texelCoords);
/* calculate average neighbor height */
ivec2 offsets[4] = ivec2[](
ivec2(-1, 0), // left
ivec2( 1, 0), // right
ivec2( 0, -1), // up
ivec2( 0, 1) // down
);
ivec2 imageSize = imageSize(waterHeightMap);
float average = 0.0;
for (int ii = 0; ii < 4; ++ii)
{
ivec2 newCoord = texelCoords + offsets[ii];
average += imageLoad(waterHeightMap, newCoord).r;
}
average *= 0.25;
info.g += (average - info.r) * 0.3;
info.g *= 0.995; // attenuation
info.r += info.g;
imageStore(waterHeightMap, ivec2(gl_GlobalInvocationID.xy), info);
// Update Normal
ivec2 texelCoords = ivec2(gl_GlobalInvocationID.xy);
vec4 info = imageLoad(waterHeightMap, texelCoords);
vec2 delta = 1.0f / ubo.u_dimAttenuation.xy;
ivec2 imageSize = imageSize(waterHeightMap);
ivec2 dxCoords = texelCoords + ivec2(1, 0);
ivec2 dyCoords = texelCoords + ivec2(0, 1);
vec3 dx = vec3(delta.x, imageLoad(waterHeightMap, dxCoords).r - info.r, 0.0);
vec3 dy = vec3(0.0, imageLoad(waterHeightMap, dyCoords).r - info.r, delta.y);
info.ba = normalize(cross(dy, dx)).xz;
imageStore(waterHeightMap, ivec2(gl_GlobalInvocationID.xy), info);

Height Map: R(Height), G(Velocity),BA(Normal.xz)
如果采用光线追踪方式渲染 Caustics,光线在经过水面时会发生较强的散射,因此需要进行采样和降噪处理。 正如前文所述,本场景的主要目标是熟悉 Vulkan Ray-Tracing API,因此 Caustics 的渲染并没有使用 光线追踪,而是通过图形管线实现,利用高度图(Height Map)数据生成 Caustics Map。
具体来说,算法根据水面与水底的高度差,结合 Height Map 计算入射光线投射到水底的变化剧烈程度。 这个剧烈程度通过相邻像素之间的差分来表示,并作为描述 Caustics 强度的依据,形成一种启发式的算法。 由于人眼对折射和 Caustics 效果的敏感度较低,尽管该算法在物理准确性上存在偏差, 但足以生成与水面相对应的 Caustics 效果,从而为观众呈现出较为自然的视觉效果。
// Calculate caustics map
// Vert
vec4 info = texture(waterHeightMap, inPos.xy * 0.5 + 0.5);
info.ba *= 0.1; // rescale normal
vec3 normal = vec3(info.b, sqrt(1.0 - dot(info.ba, info.ba)), info.a);
/* project the vertices along the refracted vertex ray */
vec3 refractedLight = refract(-light, originNormal, IOR_AIR / IOR_WATER);
vec3 ray = refract(-light, normal, IOR_AIR / IOR_WATER);
oldPos = project(inPos.xzy, refractedLight, refractedLight);
newPos = project(inPos.xzy + vec3(0.0, info.r, 0.0), ray, refractedLight);
gl_Position = vec4((newPos.xz + refractedLight.xz / refractedLight.y), 0.0, 1.0);
// Frag
layout(location = 0) in vec3 oldPos;
layout(location = 1) in vec3 newPos;
layout(location = 0) out float outFragColor;
void main()
{
float oldArea = length(dFdx(oldPos)) * length(dFdy(oldPos));
float newArea = length(dFdx(newPos)) * length(dFdy(newPos));
outFragColor = (oldArea / newArea - 1.0) * 0.2;
}

Caustics Map
Other features in Ray-Tracing Pipeline
Callable Shader 是一种支持间接调用的着色器,它允许在管线的其他着色器(如光线生成着色器、命中着色器等)中 调用特定的计算或操作。这种机制提供了更高的灵活性,能够将某些计算封装到独立的着色器中,从而优化代码结构。 Khronos Vulkan Samples 中提供了相关的用例,展示了如何利用这一特性。
Position Fetch 是一种优化机制,旨在简化光线追踪中的交点获取过程。它允许着色器在光线与物体相交时,
直接访问交点的位置,从而提高性能并增强代码的可维护性。该特性需要硬件支持,并依赖于
VK_KHR_ray_tracing_position_fetch 扩展。
Vulkan synchronization: Fence, Femaphore and Pipeline-barriers
1. Fence:用于 CPU 和 GPU 之间同步。
- CPU 可以通过
vkWaitForFences或vkGetFenceStatus等待或查询 GPU 工作是否完成。 - Fence 是全局的,同一个
Fence可用于跨 Command Buffer 的同步。
2. Semaphore用于 队列(Queue)之间同步。
- 典型场景是不同队列之间的生产者-消费者关系。例如,一个队列完成图像处理后,另一个队列可以读取图像。
- Semaphore 是 GPU 内部的,不能跨帧或在 CPU 上查询状态。
3. Pipeline Barrier:用于 同一队列中不同阶段(如 drawcall/dispatch/traceRay)的同步,确保资源访问顺序正确。
- Barrier 是显式的同步机制,通常用来解决以下问题:
- 内存依赖:确保前一个操作的写入在后一个操作读取之前完成。
- 阶段依赖:确保一个阶段完成后另一个阶段才开始。
- 资源布局切换:如从
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL切换到VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL。
void buildComputeCommandBuffer()
{
VkCommandBufferBeginInfo cmdBufInfo = vks::initializers::commandBufferBeginInfo();
VK_CHECK_RESULT(vkBeginCommandBuffer(compute.commandBuffer, &cmdBufInfo));
VkImageMemoryBarrier imageMemoryBarrier = {};
imageMemoryBarrier.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
imageMemoryBarrier.oldLayout = VK_IMAGE_LAYOUT_GENERAL;
imageMemoryBarrier.newLayout = VK_IMAGE_LAYOUT_GENERAL;
imageMemoryBarrier.image = storageImage.image;
imageMemoryBarrier.subresourceRange = { VK_IMAGE_ASPECT_COLOR_BIT, 0, 1, 0, 1 };
if (vulkanDevice->queueFamilyIndices.graphics != vulkanDevice->queueFamilyIndices.compute)
{
// Acquire barrier for compute queue
imageMemoryBarrier.srcAccessMask = 0;
imageMemoryBarrier.dstAccessMask = VK_ACCESS_SHADER_WRITE_BIT;
imageMemoryBarrier.srcQueueFamilyIndex = vulkanDevice->queueFamilyIndices.graphics;
imageMemoryBarrier.dstQueueFamilyIndex = vulkanDevice->queueFamilyIndices.compute;
vkCmdPipelineBarrier(
compute.commandBuffer,
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
VK_FLAGS_NONE,
0, nullptr,
0, nullptr,
1, &imageMemoryBarrier);
}
// prepare barrier
VkImageMemoryBarrier imageBarrier = {};
imageBarrier.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
imageBarrier.srcAccessMask = VK_ACCESS_SHADER_WRITE_BIT;
imageBarrier.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
imageBarrier.oldLayout = VK_IMAGE_LAYOUT_GENERAL;
imageBarrier.newLayout = VK_IMAGE_LAYOUT_GENERAL;
imageBarrier.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
imageBarrier.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
imageBarrier.image = waterHeightMap.image;
imageBarrier.subresourceRange = { VK_IMAGE_ASPECT_COLOR_BIT, 0, 1, 0, 1 };
// Drop pass
// -------------------------------------------------------------------------------------------------------
vkCmdBindPipeline(compute.commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, compute.pipelineDrop);
vkCmdBindDescriptorSets(compute.commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, compute.pipelineLayout, 0, 1, &compute.descriptorSet, 0, 0);
vkCmdDispatch(compute.commandBuffer, waterHeightMap.width / 16u, waterHeightMap.height / 16u, 1);
vkCmdPipelineBarrier(
compute.commandBuffer,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
0,
0, nullptr,
0, nullptr,
1, &imageBarrier);
// Update height pass
// -------------------------------------------------------------------------------------------------------
vkCmdBindPipeline(compute.commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, compute.pipelineUpdateHeight);
for (uint8_t ii = 0; ii < updateHeightTimes; ++ii)
{
vkCmdDispatch(compute.commandBuffer, waterHeightMap.width / 16u, waterHeightMap.height / 16u, 1);
vkCmdPipelineBarrier(
compute.commandBuffer,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
0,
0, nullptr,
0, nullptr,
1, &imageBarrier);
}
// Update normal pass
// -------------------------------------------------------------------------------------------------------
vkCmdBindPipeline(compute.commandBuffer, VK_PIPELINE_BIND_POINT_COMPUTE, compute.pipelineUpdateNormal);
vkCmdDispatch(compute.commandBuffer, waterHeightMap.width / 16u, waterHeightMap.height / 16u, 1);
if (vulkanDevice->queueFamilyIndices.graphics != vulkanDevice->queueFamilyIndices.compute)
{
// Release barrier from compute queue
imageMemoryBarrier.srcAccessMask = VK_ACCESS_SHADER_WRITE_BIT;
imageMemoryBarrier.dstAccessMask = 0;
imageMemoryBarrier.srcQueueFamilyIndex = vulkanDevice->queueFamilyIndices.compute;
imageMemoryBarrier.dstQueueFamilyIndex = vulkanDevice->queueFamilyIndices.graphics;
vkCmdPipelineBarrier(
compute.commandBuffer,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT,
VK_FLAGS_NONE,
0, nullptr,
0, nullptr,
1, &imageMemoryBarrier);
}
vkEndCommandBuffer(compute.commandBuffer);
}
Link中提供了关于Pipeline Barrier 使用的一些 Best Practice.

Final Scene
Miscellaneous
除了镜面反射,漫反射等出射光线较为分散的情况在光线追踪中也非常常见且具有挑战性。 在目前主流的实时光线追踪渲染器中(准确来说,主要是路径追踪渲染器),高效的采样算法和 降噪技术一直是关键的组成部分(例如 Nvidia 的 Falcor)。我也一直在相关领域进行学习, 未来可能会针对性地做一些小项目来进一步探索和实践这一技术。
References
- https://raytracing.github.io/books/RayTracingInOneWeekend.html
- https://zhuanlan.zhihu.com/p/146144853
- Vulkan Samples: https://github.com/KhronosGroup/Vulkan-Samples
- WebGL Water: https://madebyevan.com/webgl-water/
- https://github.com/NVIDIAGameWorks/Falcor
- https://iquilezles.org/articles/spherefunctions/
本博文内容为作者原创,转载请注明出处并附上原文链接,感谢支持与理解。